INTRODUCTION
We present Okutama-Action, a new video dataset for aerial view concurrent human action detection. It consists of 43 minute-long fully-annotated sequences with 12 action classes. Okutama-Action features many challenges missing in current datasets, including dynamic transition of actions, significant changes in scale and aspect ratio, abrupt camera movement, as well as multi-labeled actors. As a result, our dataset is more challenging than existing ones, and will help push the field forward to enable real-world applications.
HIGHLIGHTS
- An aerial view dataset that contains representative samples of actions in real-world airborne scenarios
- Dynamic transition of actions where, in each video, up to 9 actors sequentially perform a diverse set of actions
- A real-world challenge of multi-labeled actors where an actor performs more than one action at the same time.
- A significant increase compared to previous datasets, in number of actors and concurrent actions (up to 10 actions/actors), as well as video resolution (3840x2160) and sequence length (one minute on average).
- Dataset can be used for multiple tasks: 1- pedestrian detection 2- spatio-temporal action detection 3- (under development) multi-human tracking.
CITATION
If you find this dataset useful, please cite the following paper:

Okutama-Action: An Aerial View Video Dataset for Concurrent Human Action Detection
M. Barekatain,
M. Martí,
H. Shih,
S. Murray,
K. Nakayama,
Y. Matsuo, and
H. Prendinger
The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2017, pp. 28-35
arXiv:1706.03038
[PDF]
ANNOTATION EXAMPLES (downscaled to 720p)
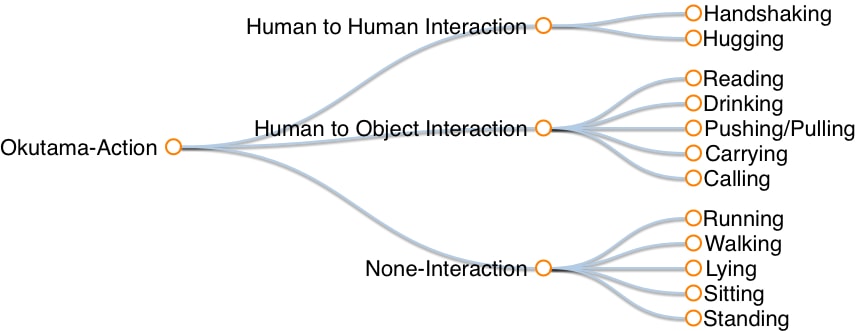
ACTION CATEGORIES
DATASET DOWNLOAD
Video Names: each video name consists of 3 integers separated by dots. The definition of these integers from left to right are:
- Drone number. Each scenario, with the exception of one, was captured using 2 drones (of different configuration) at the same time.
- Part of the day. “1” indicates morning and “2” indicates noon.
- Scenario number.
Hence, the pair of videos with the same last two integers are the same scenario with different drones configuration.
Labels: Each line contains 10+ columns, separated by spaces. The definition of these columns are:
- Track ID. please check the below part for details
- xmin. The top left x-coordinate of the bounding box.
- ymin. The top left y-coordinate of the bounding box.
- xmax. The bottom right x-coordinate of the bounding box.
- ymax. The bottom right y-coordinate of the bounding box.
- frame. The frame that this annotation represents.
- lost. If 1, the annotation is outside of the view screen.
- occluded. If 1, the annotation is occluded.
- generated. If 1, the annotation was automatically interpolated.
- label. The label for this annotation, enclosed in quotation marks. This field is always “Person”.
- (+) actions. Each column after this is an action.
There are three label files for each videos: 1- MultiActionLabels: labels for multi-action detection task. 2- SingleActionLabels: labels for single-action detection task which has been created from the multi-action detection labels (for more details please refer to our publication). In both of these files, all rows with the same “Track ID” belong to the same person for 180 frames. Then the person gets a new ID for the next 180 frames. 3- SingleActionTrackingLabels: same labels as 2, but here the ID’s are consistent. This means that each person has a unique ID in the video but will get a new one if he/she is absent for more than 90 frames.
For pedestrian detection task, the columns describing the actions should be ignored.
Sample (one 4K video and labels) link (540 MB)
Full dataset:
Training set (1280x720 frames & labels) link (5.3 GB)
Test set (1280x720 frames & labels) link (1.5 GB)
Training set (4K videos & labels) link (14 GB)
Test set (4K videos & labels) link (4 GB)
All files link
MODELS DOWNLOAD
Final trained Caffe models link.
UPDATES
- We will soon release the metadata for each video sequence, namely camera angle, speed and altitude of the drones.
- Test set labels are now available.
- Links have been updated, now hosted on AWS for easier download.
- Links have been updated, now hosted on Dropbox.
DEVELOPERS TEAM
The creation of this dataset was supported by Prendinger Lab at the National Institute of Informatics, Tokyo, Japan. We are also grateful for financial support and the provision of GPU power from Matsuo Lab at the University of Tokyo.





LICENSE

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
If you are interested in commercial usage you can contact us for further options.